In today’s modern business landscape, data is the new oil, a critical asset that can drive organizational success. One of the key technologies enabling effective data management and analytics in enterprises is the Data Lake. In this article, we will explore the intricacies of Data Lakes, delving into their structure, functionality, and the pivotal role they play in enterprise data management.
If you prefer video format, please watch the video below and be sure to subscribe!
What exactly is a Data Lake?
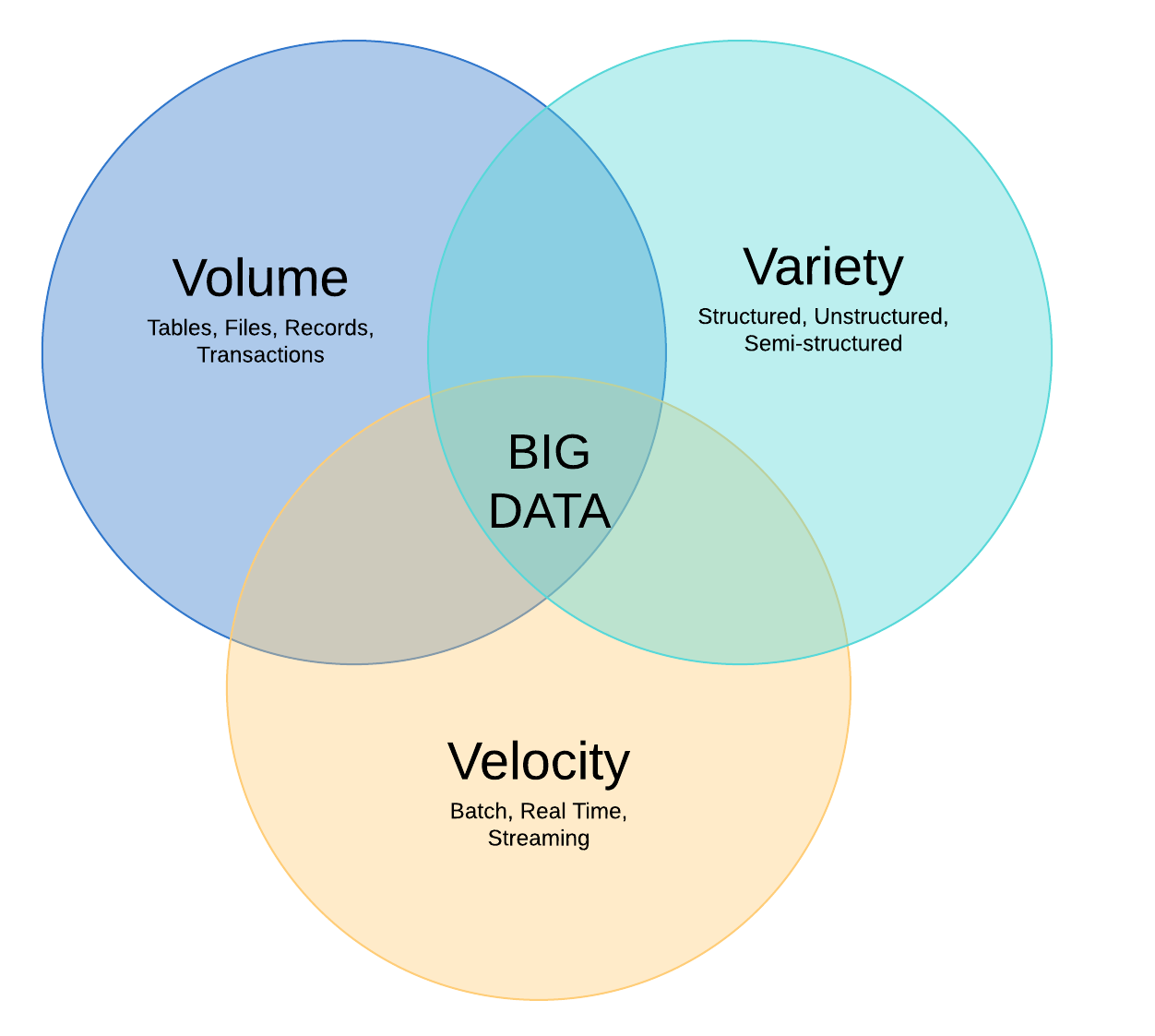
Data Lakes have emerged in the past couple of years as an important component in managing the explosion of Data Volume, Data Variety, and Data Velocity, also known as the 3 Vs, that a typical enterprise organization might produce.
A Data Lake provides a centralized reservoir that allows these organizations to store structured (think relational databases), semi-structured (think NoSQL) and unstructured data (think images and videos) at scale. The data in the data lake is analytics-ready and capable of providing valuable insights.
For many of our enterprise customers, data is a key driver for strategic decision-making, and when we setup their data lakes it enables them to harness their data effectively, ensuring it is accessible, manageable, and ready to deliver actionable insights when they need it.
A Brief History of Data Lakes
Before the concept of data lakes, organizations primarily relied on relational databases and data warehouses. These systems were structured, schema based, and optimized for specific use cases.
With the advent of the internet, social media, IoT, and other technologies, the amount of data generated exploded. Not only was there more data, but it also came in varied formats: structured, semi-structured, and unstructured. Traditional data storage solutions struggled to handle this diversity and scale efficiently.
Around the mid-2000s, technologies like Hadoop emerged, that allowed for distributed processing of large data sets across a cluster of computers with its Hadoop Distributed File System, or HDFS for short, technology which his more of a file storage system than a database. In HDFS, you don’t need to define a schema before storing data. This means you can store files irrespective of their format—whether they’re CSV files, images, logs, or any other data format.
The term data lake was coined to describe this new approach to data storage. Instead of the organized, clean, and structured “water” of traditional databases, a data lake is more like a natural body of water where data flows in from various sources and paths and accumulates in its raw, unfiltered form.
Key Features of a Data Lake
You’re probably asking yourself what differentiates a Data Lake from other storage formats, for example a simple filesystem? Well there ae several key characteristics of a data lake:
The Type of Data that can be stored: Data lakes can store any type of data—structured, semi-structured, or unstructured. I guess this is similar to a file system.
Schema Flexibility: Data lakes support schema-on-read as opposed to schema-on-write. This means you can store data without a predefined structure and define the schema when you’re ready to actually read or analyze the data, rather than before storing it.
Scale: Data lakes are designed to handle massive volumes of data, scaling from terabytes to exabytes, which goes beyond the typical capacities of traditional databases.
Raw Data Storage: Data can be stored in its raw, native format. This contrasts with other systems where data often needs to be transformed or cleansed before storage.
Integration with Big Data Tools: Data lakes are typically compatible with big data processing tools like Hadoop, Spark, and others, allowing for distributed processing and analysis of the vast datasets they contain.
Cost-Efficiency: Many data lake solutions, especially those in the cloud, offer a cost-effective means of storing large amounts of data due to optimized storage tiers and data compression methods.
Cloud Based Data Lake Options
Nearly every major cloud provider offers their own version of data lake technology because they have become essential for storing these vast and varied datasets that organizations produce and they have great integration points with other cloud resources that enable the required scaling for big data analytics and advanced machine learning, which modern businesses increasingly rely upon for insights and innovation.
Azure has Azure Data Lake
AWS has Amazon S3 with Amazon Lake Formation
GCP does not have a specific service called “Data Lake” like some other cloud providers, but you can build a data lake architecture using Cloud Storage and Big Query
Databricks has Delta Lake, an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads and known for ensuring reliability to data lakes.

Data Lake Scenario
So now that we understand what a Data Lake is and how it came to be I wanted to go over a real scenario where a data lake might come in useful.
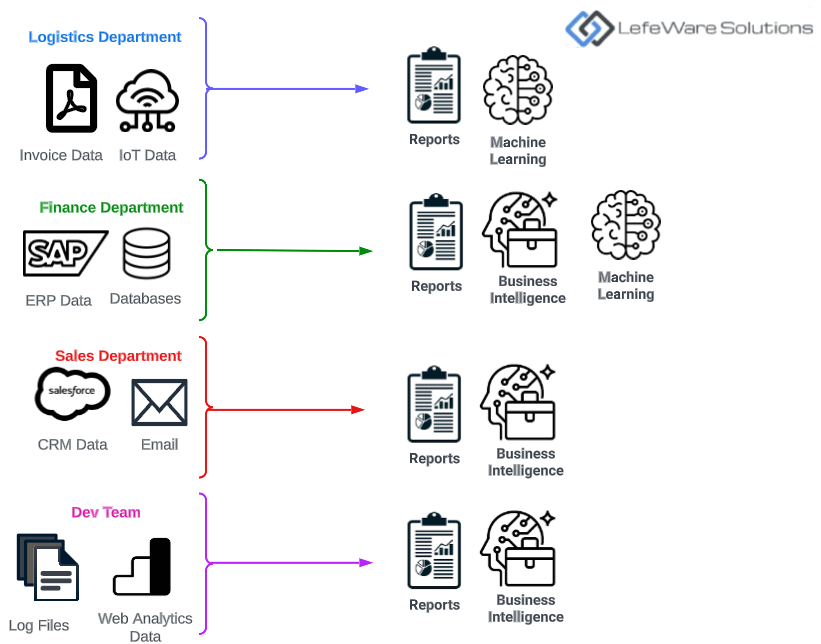
One of our large clients at LefeWare Solutions in the manufacturing industry recently reached out to us because they had several different departments, each producing their own data in databases, their own logs, IoT data etc.
The sales/marketing department had data related to customer preferences, buying behaviors, and campaign outcome that they might be storing in their CRM.
The finance department had data related to sales, revenues, and costs in a relational database
The operations department had data related to inventory, supply chain, and logistics, and IoT device telemetry in a semi structured log files.
The dev team had data related to a custom inventory app that had log files and other mobile and web analytics data
The organization had not implemented a centralized data lake and were facing several challenges.
Each team I just mentioned would store and manage their data separately, in different formats and platforms.
Data sharing between those departments was cumbersome and time-consuming, involving manual processes and there were often data integrity issues, in other words data silos.
Analyzing data across these departments would was complex and challenging, as it required integrating data from different sources and formats.
Ultimately the organization struggled to derive comprehensive, actionable insights due to the fragmented view of data.
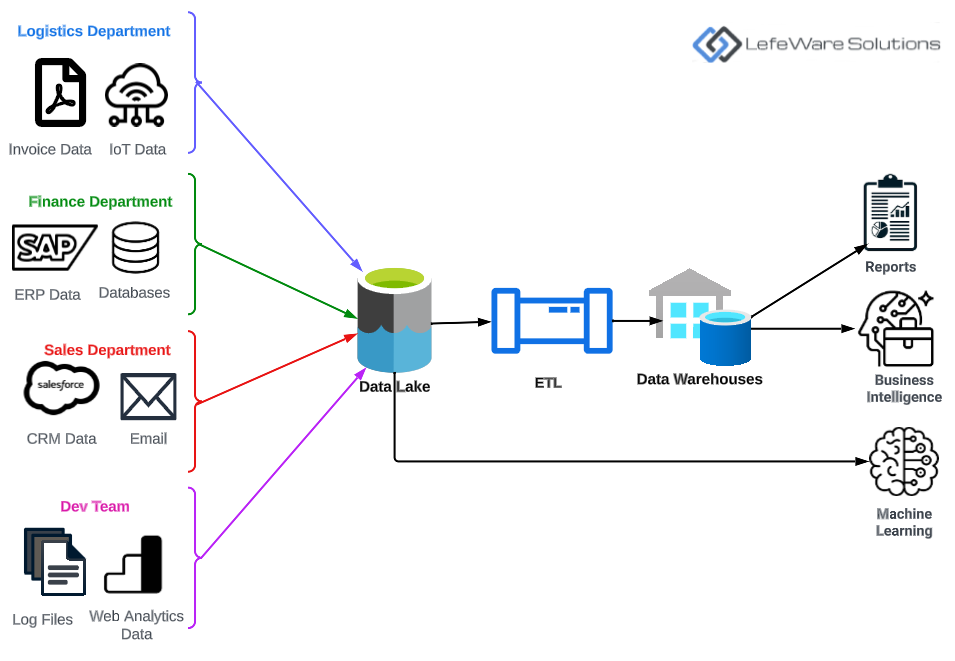
- All the data from different departments was now stored in a centralized, unified repository, regardless of its source, format, or type.
- Data could be accessed and analyzed by any department, enabling cross-functional analysis and insights. For example, the marketing team could now easily access and analyze financial data to measure the ROI of different campaigns.
- It allowed for advanced organization wide analytics, machine learning models, and AI that could be applied to the entire dataset, enabling the organization to derive more sophisticated insights and predictions.
- Data governance, security, and compliance was now much easier to manage and could be done more effectively at an organizational level, instead of being handled separately by each department.
Conclusion
So In essence, Data Lakes have transformed the way enterprises store, manage, and analyze their data, providing a flexible and scalable solution that can harness the power of big data.
If you’re a growing organization that’s looking to gain actionable insights from your data, you should be aware that implementing a Data Lake comes with its own set of challenges like ensuring data quality, security, and governance, contact us today. Our team of dedicated data engineers at LefeWare Solutions can help implement and ensure your data Solutions are using the most robust data governance policies, utilizing data encryption, and ensuring data quality management of your data.



